最近(很久之前的最近)在弄硬件,买了一块彩屏,需要字库,所以就把很久以前会的知识拿出来温习了一遍。果然好多都记忆模糊了。网上的代码我看过,很多都有问题,这里我帖出来的是我自己写的代码,没有问题。
HZK16字库是符合GB2312标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个。其中一级汉字有 3755个,按声序排列,二级汉字有3008个,按偏旁部首排列。
我们在一些应用场合根本用不到这么多汉字字模,所以在应用时就可以只提取部分字体作为己用。
HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。
我们知道一个GB2312汉字是由两个字节编码的,范围为0xA1A1~0xFEFE。A1-A9为符号区,B0-F7为汉字区。每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域)。
下面以汉字"我"为例,介绍如何在HZK16文件中找到它对应的32个字节的字模数据。前面说到一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的位号。其中,每个区记录94个汉字,位号为该字在该区中的位置。所以要找到"我"在hzk16库中的位置就必须得到它的区码和位码。
区码:汉字的第一个字节-0xA0 (因为汉字编码是从0xA0区开始的, 所以文件最前面就是从0xA0区开始, 要算出相对区码)
位码:汉字的第二个字节-0xA0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:
offset=(94*(区码-1)+(位码-1))*32
注解:
- 区码减1是因为数组是以0为开始而区号位号是以1为开始的
- (94*(区号-1)+位号-1)是一个汉字字模占用的字节数
- 最后乘以32是因为汉字库文应从该位置起的32字节信息记录该字的字模信息(前面提到一个汉字要有32个字节显示)
我画的图示:
+--16bit,2bytes--+○○○○○●○○●○○○○○○○ | -> 0x04,0x80
○○○○●●●○●○●○○○○○ | -> 0x0E,0xA0
○●●●●○○○●○○●○○○○ | -> 0x78,0x90
○○○○●○○○●○○●○○○○ | -> 0x08,0x90
○○○○●○○○●○○○○●○○ | -> 0x08,0x84
●●●●●●●●●●●●●●●○ | -> 0xFF,0xFE
○○○○●○○○●○○○○○○○ | -> 0x08,0x80
○○○○●○○○●○○●○○○○ |16bit -> 0x08,0x90
○○○○●○●○●○○●○○○○ |2bytes -> 0x0A,0x90
○○○○●●○○○●●○○○○○ | -> 0x0C,0x60
○○○●●○○○○●○○○○○○ | -> 0x18,0x40
○●●○●○○○●○●○○○○○ | -> 0x68,0xA0
○○○○●○○●○○●○○○○○ | -> 0x09,0x20
○○○○●○●○○○○●○●○○ | -> 0x0A,0x14
○○●○●○○○○○○●○●○○ | -> 0x28,0x14
○○○●○○○○○○○○●●○○ + -> 0x10,0x0C
所以,'我'在HZK16 16*16点阵字库的存放的序列为:
(一行一行地保存,共16行,每行2个字节, 共32个字节)
0A 90 0C 60 18 40 68 A0 09 20 0A 14 28 14 10 0C
就像下面这样:
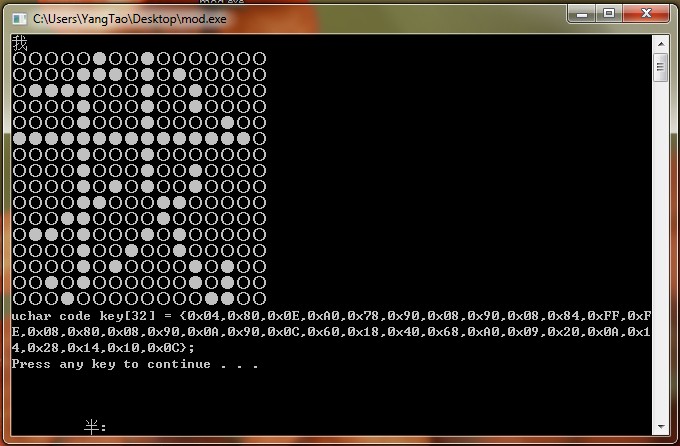
以下是我自己写的示例程序, 可以自己修改成其它的数据格式.(很简单, 所以没写注释)。
示例源代码
版本1
#includeint main(void) { FILE* fphzk = NULL; int i, j, k, offset; int flag; unsigned char buffer[32]; unsigned char word[3] = "我"; unsigned char key[8] = { 0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01 }; fphzk = fopen("hzk16", "rb"); if(fphzk == NULL){ fprintf(stderr, "error hzk16\n"); return 1; } offset = (94*(unsigned int)(word[0]-0xa0-1)+(word[1]-0xa0-1))*32; fseek(fphzk, offset, SEEK_SET); fread(buffer, 1, 32, fphzk); for(k=0; k<32; k++){ printf("%02X ", buffer[k]); } for(k=0; k<16; k++){ for(j=0; j<2; j++){ for(i=0; i<8; i++){ flag = buffer[k*2+j]&key[i]; printf("%s", flag?"●":"○"); } } printf("\n"); } fclose(fphzk); fphzk = NULL; return 0; }
版本2
#include#include int main(void) { FILE* fphzk = NULL; int i, j, k, offset; int flag; unsigned char buffer[32]; unsigned char word[5]; unsigned char key[8] = { 0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01 }; fphzk = fopen("hzk16", "rb"); if(fphzk == NULL){ fprintf(stderr, "error hzk16\n"); return 1; } while(1){ printf("输入要生成字模的汉字(多个):"); for(;;){ fgets((char*)word, 3, stdin); if(*word == '\n') break; offset = (94*(unsigned int)(word[0]-0xa0-1)+(word[1]-0xa0-1))*32; fseek(fphzk, offset, SEEK_SET); fread(buffer, 1, 32, fphzk); for(k=0; k<16; k++){ for(j=0; j<2; j++){ for(i=0; i<8; i++){ flag = buffer[k*2+j]&key[i]; printf("%s", flag?"●":"○"); } } printf("\n"); } printf("uchar code key[32] = {"); for(k=0; k<31; k++){ printf("0x%02X,", buffer[k]); } printf("0x%02X};\n", buffer[31]); printf("\n"); } } fclose(fphzk); fphzk = NULL; return 0; }
相关资源
- 程序及源代码下载:mod.7z
- 各种字库下载地址:http://pan.baidu.com/share/link?shareid=2514580636&uk=320828865
本文由 cswxzx 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jan 17, 2016 at 03:42 pm